Artificial Intelligence & Quantum Artificial Intelligence – Hybrid Quantum-Classical AI
We continue in this installment of The Bleeding Edge to go into further detail on quantum computing and AI. Much of what we talk about here is a projection of the possible. What actually happens may diverge from our roadmap we lay down.
Hybrid Quantum-Classical AI
Hybrid quantum-classical AI combines classical and quantum computers to perform AI tasks, leveraging each system’s unique strengths to solve problems that are too complex for either alone. Classical systems handle data management and optimization, while quantum processors tackle computationally intensive parts of algorithms, like feature manipulation in high-dimensional spaces, to enhance model accuracy and efficiency. This “best-of-both-worlds” approach is a practical way to benefit from early quantum capabilities while navigating current hardware limitations, forming a bridge to fully quantum AI.
AI Calculation in Neural Networks and Transformers in NVIDA Chips
NVIDIA chips, particularly their Graphics Processing Units (GPUs), are designed to accelerate AI calculations in neural networks and transformers through several key architectural features and optimizations:
- Parallel Processing Power:
GPUs excel at parallel processing, enabling them to perform thousands of computations simultaneously. This is crucial for neural networks and transformers, which rely heavily on matrix and vector operations that can be broken down into many independent calculations. - Tensor Cores:
NVIDIA’s Tensor Cores are specialized processing units within their GPUs specifically designed to accelerate matrix multiply-accumulate operations, which are fundamental to deep learning and transformer models. They support various precision formats, including FP8, FP16, and TF32, optimizing for both speed and accuracy. - Transformer Engine:
Introduced with the Hopper architecture (e.g., H100 GPU), the Transformer Engine dynamically manages numerical precision (e.g., switching between FP8 and FP16) within each layer of a neural network. This allows for faster computations while maintaining model accuracy by intelligently choosing the optimal precision for each operation.
Transformers (used in GPT, BERT, etc.) have two main computational bottlenecks:
Attention Mechanism
Core formula:
- Q, K, V are matrices (queries, keys, values).
- Requires matrix multiplications for QKT and the final multiplication with VVV.
- NVIDIA accelerates this with:Fused kernels (combine multiple GPU operations into one to reduce memory reads/writes). FlashAttention on newer GPUs (uses tiling in SRAM to avoid high DRAM bandwidth costs).
Feed-Forward Network (FFN) in Transformers
- Large MLP layer: another two big GEMMs + activation (usually GELU).
- Tensor Cores run these in mixed precision for maximum throughput.
Precision & Speed Optimizations
NVIDIA uses:
- Mixed precision training (AMP) → FP16/BF16 for most ops, FP32 for sensitive accumulations.
- Quantization (INT8 or INT4) for inference to reduce compute and memory usage.
- Sparsity (Ampere+ GPUs) → Skip zero weights to double throughput for sparse models.
NVIDIA H100 in AI Workloads
- Transformer Engine: Hardware that automatically switches precision (FP8, BF16, FP16, FP32) to maximize speed without losing accuracy.
- Memory Bandwidth: Up to 3 TB/s.
- Performance: Over 1,000 TFLOPS (FP8) for transformer inference/training.
- Tensor Core GPU: The NVIDIA Hopper Architecture provides extensive expansion of their matrix processing cores. These diagrams show the H100 FP16/FP8 tensor cores.
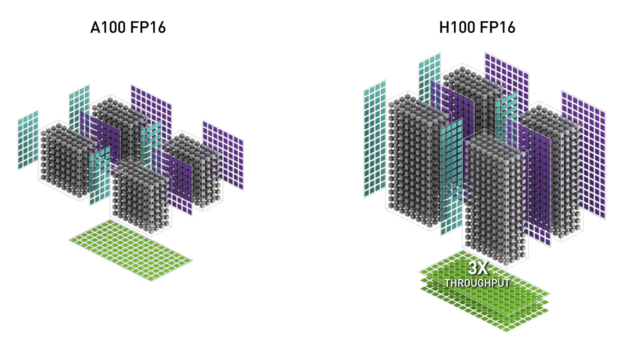
H100 FP16 Tensor Core has 3x throughput compared to A100 FP16 Tensor Core

H100 FP8 Tensor Core has 6x throughput compared toA100 FP16 Tensor Core
- High-Bandwidth Memory (HBM):
NVIDIA GPUs are equipped with HBM, providing significantly higher memory bandwidth compared to traditional DRAM. This is critical for large-scale AI models, as it allows for faster data transfer between the processing units and memory, preventing bottlenecks during training and inference. - NVLink:
NVLink is a high-speed interconnect technology developed by NVIDIA that enables direct GPU-to-GPU communication at much higher bandwidths than PCIe. This is essential for scaling up AI workloads across multiple GPUs, allowing for efficient distributed training of massive neural networks and transformers.